标本数据分析工作台-用户指南
在线分析平台概述
本计算平台的研发目的是提供一个在线的标本分析环境,在不需要大量下载标本数据的情况下, 可以根据用户的分析需求,运行用户代码的软件框架,可以将分析的结果按照用户的代码进行 输出,形成分析报告。
用户代码,目前支持 Javascript 代码,主要是为了满足在网页上运行要求。
快速入门
案例:如何获取一个采集人的采集历史?
每个标本馆都有一些重要的采集人,如果我们想整理他们的采集历史,该如何做呢?
以下以整理“张振万”先生的采集历史为例,简要说明步骤:
1. 在我们的分析工作台当中,在分析程序列表中,选择 “标本采集历史分析” ;

2. 在标本数据集筛选步骤当中,在采集人输入框键入“张振万”
3. 看到 Step2、Step3 当中已有用户代码,如果需要可以自己修改(需要有权限)
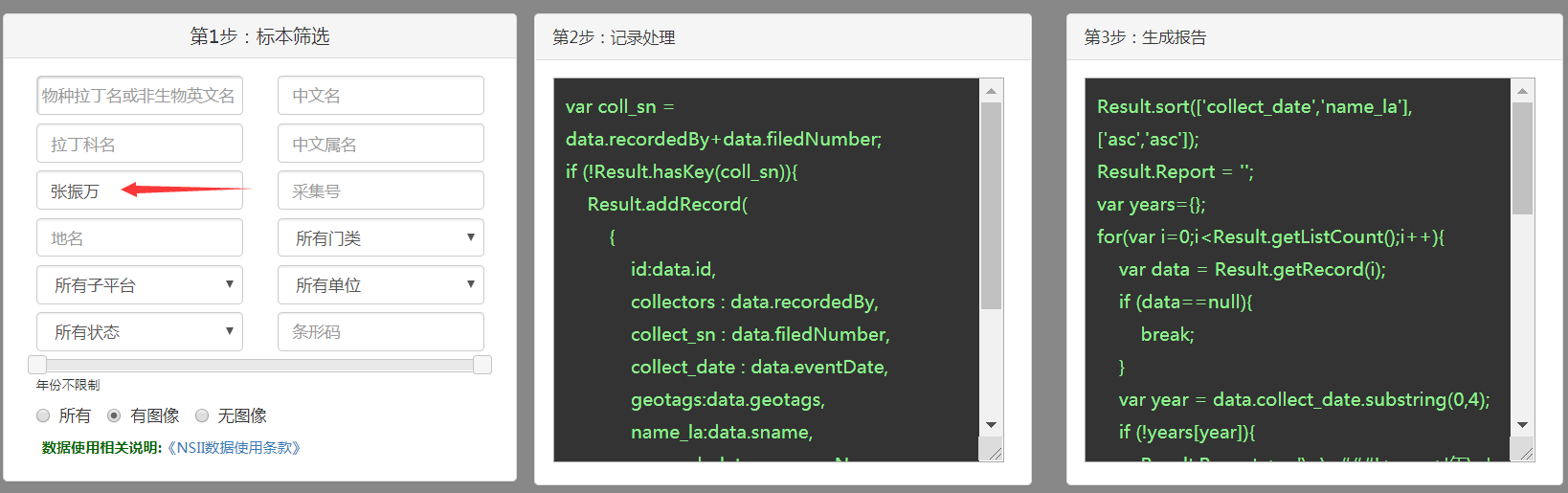
4. 点击开始分析按钮
5. 可以看到数据分析的结果已经整理成文档,按年份排列整齐


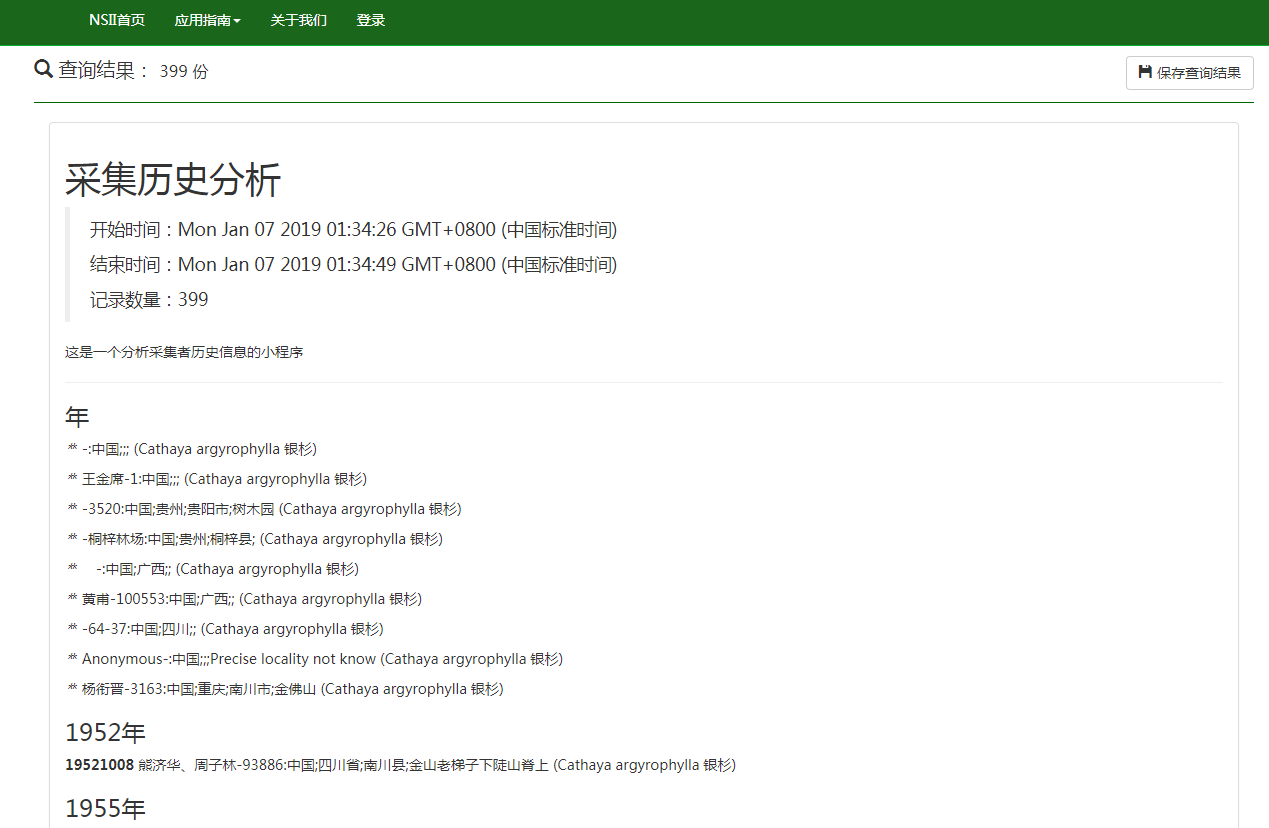
案例:如何获取一个物种的采集历史?
以下以 银杉(Cathaya argyrophylla) 的采集历史为例,简要说明步骤:
1. 在我们的分析工作台当中,在分析程序列表中,选择 “标本采集历史分析” ;
2. 在标本数据集筛选步骤当中,在中文名输入框键入“银杉”
3. 看到 Step2、Step3 当中已有用户代码,如果需要可以自己修改(需要有权限)

4. 点击开始分析按钮
5. 可以看到数据分析的结果已经整理成文档,按年份排列整齐

使用文档
1.计算目标分析与统计模型建立
NSII标本在线计算平台,有两个限制条件:
(1) 在线运行分析代码
(2) 海量的数据不下载到用户本地,直接在线运行。
因此我们采用的解决方案分别是:
(1) 用户脚本采用 Javascript 语言,可以实现在线运行的目标;
(2) 数据不下载,直接在线分析,主要解决方案是统一后台的API,实现在线调用。
为了实现这两个设计目标,首先要分析工作的目标,就是统计的结果是什么?
要为结果创建一个模型,在Javascript来说,就是创建一个数据对象。
这个模型要能够装载标本记录的分析数据,实现累计统计效果。
2.设置标本过滤条件
NSII 的标本数据是海量的,因此首先需要对标本进行过滤。
通常我们的统计对象都不是全部的标本数据,而只是需要其中的一部分。
过滤条件的设置与 NSII 的标本搜索框时基本一致的,因此如果你已经熟悉了 NSII 的标本搜索,则非常容易理解。
3.单条记录处理过程
为了显示海量标本的计算分析,我们化繁为简,只需要写出来一份标本记录面对统计模型应该如何处理。 这样的处理代码就是Step2所需要的核心代码。
只要撰写了一条记录的处理流程,系统分析框架会自动通过API调用符合条件的已经过滤好的数据集, 逐条进行累积分析。最终实现海量记录的统计。
4.统计模型的结果输出
在每条记录统计后,统计模型都会发生改变,这时候,用户的Step3的代码就会被调用,实时改变输出结果。
5.个性化脚本的开发
用户的个性化脚本可以自行开发。只需要遵守这个计算框架的约定即可。
但是只有注册用户才能提交自己的脚本。
提交的脚本必须通过管理员的审核后才能正式上线共享。
6.脚本的安全性要求
1. numFound 机制 -- 要求首先在第一次的筛选中,结果数据集numFound不能超过阈值
2. 用户代码机制 -- 用户代码不能获取隐秘数据
3. 用户审核机制 -- 只有特定用户才能运行自己写的代码,发布的共享代码必须经过审核
4. 沙盒机制 -- API以及应用环境是沙盒机制,不会威胁到真正的前台或后台安全
5. 结构校验 -- Model通过界面引导生成,不能随意写;
Result可以写,但是Result字段与成员必须与Model对应
data字段是固定的,不能出现未定义的字段
6. 简易编译 -- 将程序解析为变量与操作符,可以使用数学函数、自定义变量于自定义函数
但是不能出现向后台提交、网络请求等操作;防止安全事故